
基本的SELECT语句
SQL基本概述
SQL背景知识
SQL(Structured Query Language,结构化查询语言)是使用关系模型的数据库应用语言, 与数据直接打交道 ,由 IBM 上世纪70年代开发出来。后由美国国家标准局(ANSI)开始着手制定SQL标准,先后有 SQL-86 , SQL-89 , SQL-92 , SQL-99 等标准。
SQL 有两个重要的标准: 分别是 SQL92 和 SQL99,它们分别代表了 92 年和 99 年颁布的 SQL 标准,我们今天使用的 SQL 语言依然遵循这些标准。不同的数据库生产厂商都支持SQL语句,但都有特有内容
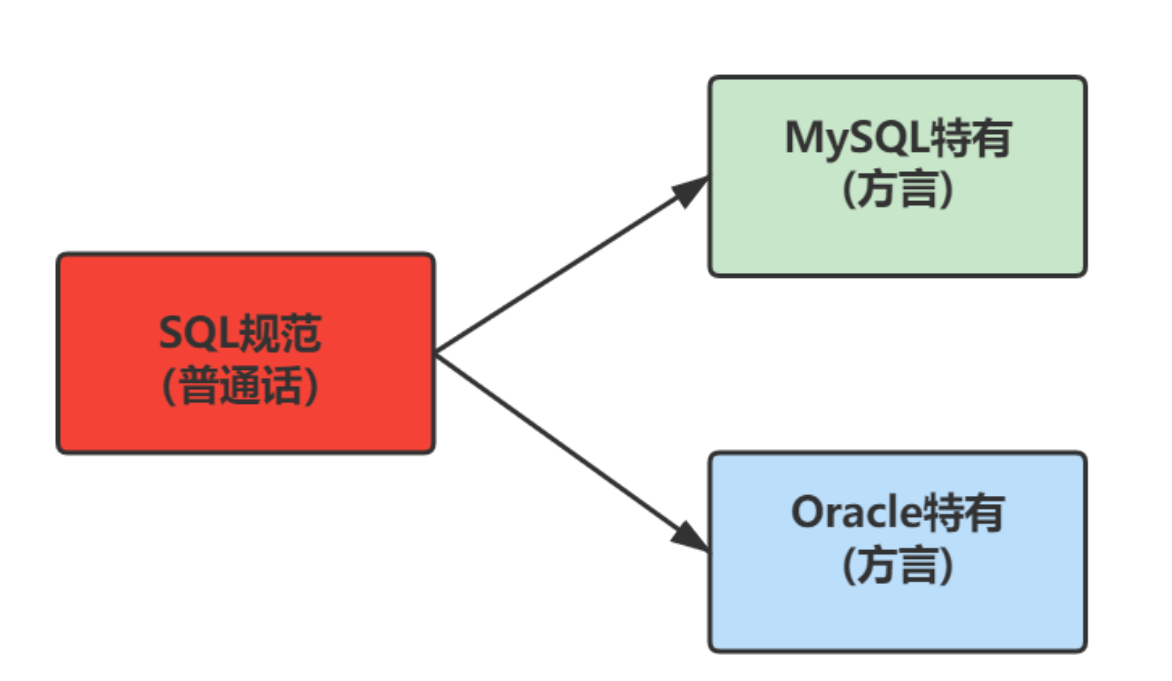
SQL分类
因为查询语句使用的非常的频繁,所以很多人把查询语句单拎出来一类:DQL(数据查询语言)。
还有单独将 COMMIT 、 ROLLBACK 取出来称为TCL (Transaction Control Language,事务控制语言)。
DDL(Data Definition Languages、数据定义语言): 这些语句定义了不同的数据库、表、视图、索引等数据库对象,还可以用来创建、删除、修改数据库和数据表的结构
- 主要的语句关键字包括 CREATE 、 DROP 、 ALTER 等
DML(Data Manipulation Language、数据操作语言): 用于添加、删除、更新和查询数据库记录,并检查数据完整性
- 主要的语句关键字包括 INSERT 、 DELETE 、 UPDATE 、 SELECT 等。SELECT是SQL语言的基础,最为重要
DCL(Data Control Language、数据控制语言),用于定义数据库、表、字段、用户的访问权限和安全级别
- 主要的语句关键字包括 GRANT 、 REVOKE、COMMIT、ROLLBACK、SAVEPOINT 等
SQL规范
基本规范
-
SQL 可以写在一行或者多行。为了提高可读性,各子句分行写,必要时使用缩进
-
每条命令以
;或\g或\G结束 -
关键字不能被缩写也不能分行
-
关于标点符号
- 必须保证所有的()、单引号、双引号是成对结束的
- 必须使用英文状态下的半角输入方式
- 字符串型和日期时间类型的数据可以使用单引号
(' ')表示 - 列的别名,尽量使用双引号
(" "),而且不建议省略as
SQL的大小写规范
- MySQL 在
Windows环境下是大小写不敏感的 - MySQL 在
Linux环境下是大小写敏感的- 数据库名、表名、表的别名、变量名是严格区分大小写的
- 关键字、函数名、列名(或字段名)、列的别名(字段的别名) 是忽略大小写的
- 推荐采用统一的书写规范 :
- 数据库名、表名、表别名、字段名、字段别名等都小写
- SQL 关键字、函数名、绑定变量等都大写
注释
可以使用如下格式的注释结构 :
单行注释:#注释文字(MySQL特有的方式) 单行注释:-- 注释文字(--后面必须包含一个空格。) 多行注释:/* 注释文字 */
命名规则
规则描述
- 数据库、表名不得超过30个字符,变量名限制为29个
- 必须只能包含 A–Z, a–z, 0–9, _共63个字符
- 数据库名、表名、字段名等对象名中间不要包含空格
- 同一个MySQL软件中,数据库不能同名;同一个库中,表不能重名;同一个表中,字段不能重名
- 必须保证你的字段没有和保留字、数据库系统或常用方法冲突。如果坚持使用,请在SQL语句中使用 `( 着重号)引起来
- 保持字段名和类型的一致性,在命名字段并为其指定数据类型的时候一定要保证一致性。假如数据类型在一个表里是整数,那在另一个表里可就别变成字符型了
举例说明
以下两句是一样的,不区分大小写
# 以下两句是一样的,不区分大小写 show databases; SHOW DATABASES;
#创建表格 #create table student info(...); #表名错误,因为表名有空格 create table student_info(...);
#其中order使用``飘号,因为order和系统关键字或系统函数名等预定义标识符重名了 CREATE TABLE `order`();
select id as "编号", `name` as "姓名" from t_stu; #起别名时,as都可以省略 select id as 编号, `name` as 姓名 from t_stu; #如果字段别名中没有空格,那么可以省略"" select id as 编 号, `name` as 姓 名 from t_stu; #错误,如果字段别名中有空格,那么不能省略""
阿里开发手册
建表规约
- 【强制】表达是与否概念的字段,必须使用
is_xxx的方式命名,数据类型是unsigned tinyint(1 表示是,0 表示否)。
-
说明:任何字段如果为非负数,必须是 unsigned。
-
注意:POJO 类中的任何布尔类型的变量,都不要加 is 前缀,所以,需要在
<resultMap>设置从 is_xxx 到 Xxx 的映射关系。数据库表示是与否的值,使用 tinyint 类型,坚持is_xxx的命名方式是为了明确其取值含义与取值范围。
正例:表达逻辑删除的字段名 is_deleted,1 表示删除,0 表示未删除。
- 【强制】表名、字段名必须使用小写字母或数字,禁止出现数字开头,禁止两个下划线中间只出现数字。数据库字段名的修改代价很大,因为无法进行预发布,所以字段名称需要慎重考虑。
- 说明:MySQL 在 Windows 下不区分大小写,但在 Linux 下默认是区分大小写。因此,数据库名、表名、字段名,都不允许出现任何大写字母,避免节外生枝。
正例:aliyun_admin,rdc_config,level3_name
反例:AliyunAdmin,rdcConfig,level_3_name
- 【强制】表名不使用复数名词。
- 说明:表名应该仅仅表示表里面的实体内容,不应该表示实体数量,对应于 DO 类名也是单数形式,符合表达习惯
-
【强制】禁用保留字,如 desc、range、match、delayed 等,请参考 MySQL 官方保留字。
-
【强制】主键索引名为
pk_字段名;唯一索引名为uk_字段名;普通索引名则为idx_字段名
- 说明:pk_ 即 primary key;uk_ 即 unique key;idx_ 即 index 的简称
- 【强制】小数类型为
decimal,禁止使用 float 和 double。
- 说明:在存储的时候,float 和 double 都存在精度损失的问题,很可能在比较值的时候,得到不正确的结果。如果存储的数据范围超过 decimal 的范围,建议将数据拆成整数和小数并分开存储。
-
【强制】如果存储的字符串长度几乎相等,使用 char 定长字符串类型
-
【强制】varchar 是可变长字符串,不预先分配存储空间,长度不要超过 5000,如果存储长度大于此值,定义字段类型为 text,独立出来一张表,用主键来对应,避免影响其它字段索引效率。
-
【强制】表必备三字段:id, create_time, update_time。
- 说明:其中 id 必为主键,类型为 bigint unsigned、单表时自增、步长为 1。create_time, update_time的类型均为
datetime类型,前者现在时表示主动式创建,后者过去分词表示被动式更新。
- 【推荐】表的命名最好是遵循“业务名称_表的作用”。
- 正例:alipay_task / force_project / trade_config
-
【推荐】库名与应用名称尽量一致
-
【推荐】如果修改字段含义或对字段表示的状态追加时,需要及时更新字段注释
-
【推荐】字段允许适当冗余,以提高查询性能,但必须考虑数据一致。冗余字段应遵循
- 不是频繁修改的字段。
- 不是唯一索引的字段
- 不是 varchar 超长字段,更不能是 text 字段
正例:各业务线经常冗余存储商品名称,避免查询时需要调用 IC 服务获取
-
【推荐】单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
-
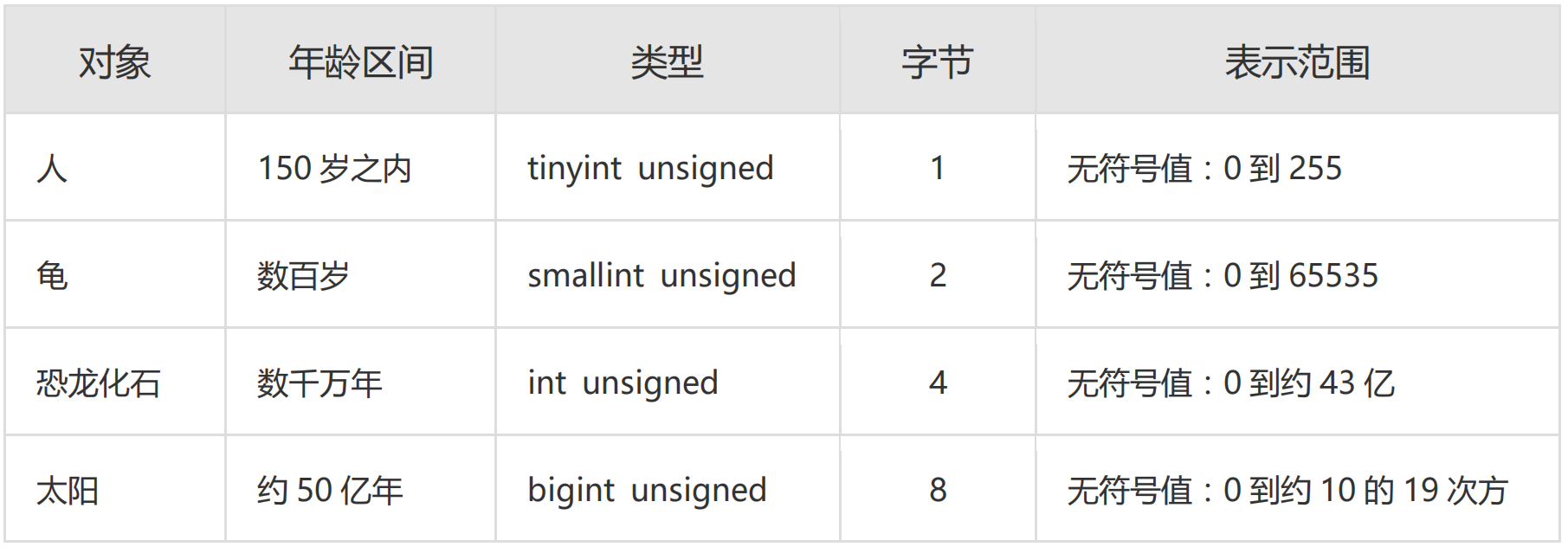
【参考】合适的字符存储长度,不但节约数据库表空间、节约索引存储,更重要的是提升检索速度
正例:无符号值可以避免误存负数,且扩大了表示范围
索引规约
基本的SELECT语句
SELECT
一般情况下,除非需要使用表中所有的字段数据,最好不要使用通配符‘*’。使用通配符虽然可以节省输入查询语句的时间,但是获取不需要的列数据通常会降低查询和所使用的应用程序的效率。
通配符的优势是,当不知道所需要的列的名称时,可以通过它获取它们。在生产环境下,不推荐你直接使用 SELECT * 进行查询
MySQL中的SQL语句是不区分大小写的,因此SELECT和select的作用是相同的,但是,许多开发人员习惯将关键字大写、数据列和表名小写,读者也应该养成一个良好的编程习惯,这样写出来的代 码更容易阅读和维护
# SELECT SELECT 1; # SELECT 全部字段 SELECT * FROM departments; # SELECT 字段 USE atguigudb; SELECT department_id, department_name FROM departments;
列的别名
重命名一个列便于计算紧跟列名,也可以在列名和别名之间加入关键字AS,别名使用双引号,以便在别名中包含空格或特殊的字符并区分大小写。 AS 可以省略 建议别名简短,见名知意
SELECT department_id AS "id", department_name AS "name" FROM departments;
去除重复行
默认情况下,查询会返回全部行,包括重复行 , 在SELECT语句中使用关键字DISTINCT去除重复行 , DISTINCT 其实是对后面所有列名的组合进行去重
SELECT DISTINCT department_id,salary FROM employees;
如果你想要看都有哪些不同的部门(department_id),只需要写 DISTINCT department_id 即可,后面不需要再加其他的列名了
空值参与运算
所有运算符或列值遇到null值,运算的结果都为null ,
一定要注意,在 MySQL 里面, 空值不等于空字符串。一个空字符串的长度是 0,而一个空值的长度是空。而且,在 MySQL 里面,空值是占用空间的
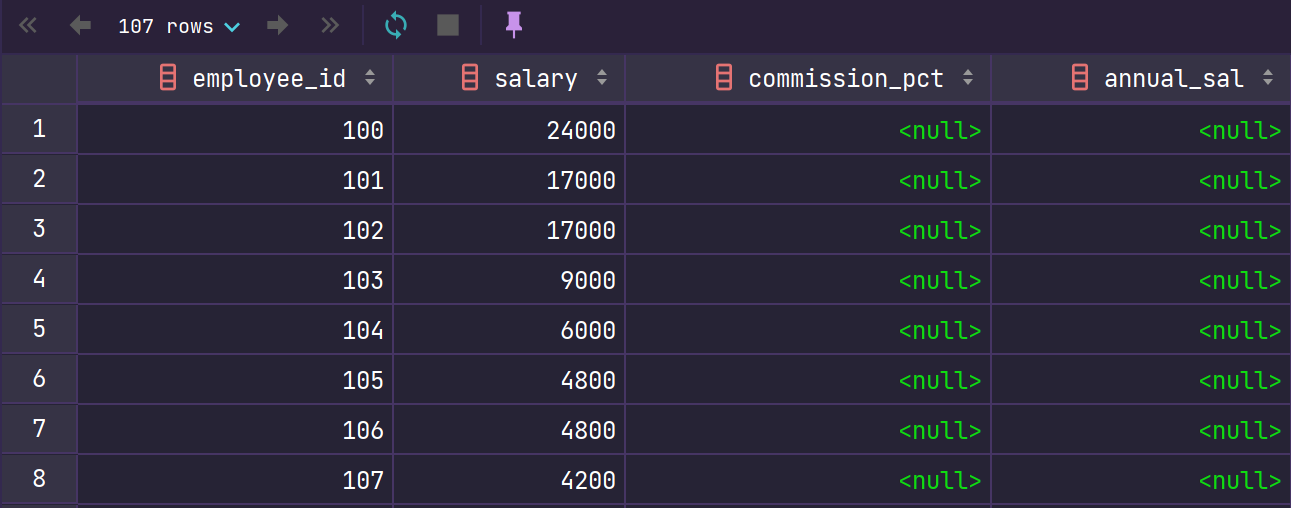
SELECT employee_id,salary,commission_pct, 12 * salary * (1+commission_pct) AS "annual_sal" from employees;
着重号
我们需要保证表中的字段、表名等没有和保留字、数据库系统或常用方法冲突。如果真的相同,请在SQL语句中使用一对 `` (着重号)引起来
# SELECT * FROM ORDER , 这是错误的, 因为 ORDER 和 MySQL 关键字相同了 SELECT * FROM `order`
SELECT 查询还可以对常数进行查询。对的,就是在 SELECT 查询结果中增加一列固定的常数列。这列的取值是我们指定的,而不是从数据表中动态取出的。
你可能会问为什么我们还要对常数进行查询呢?
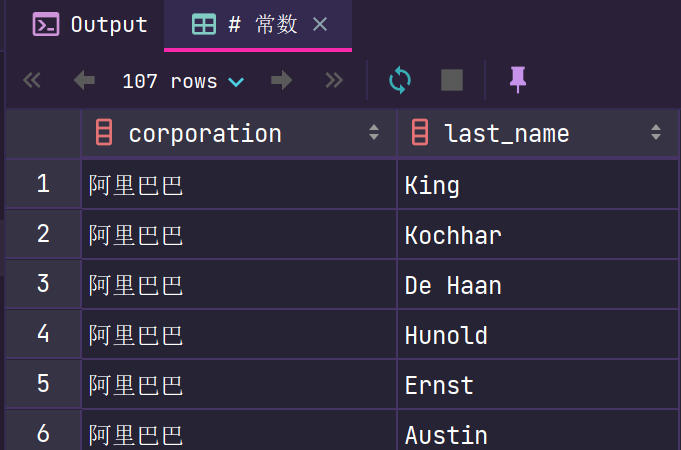
SQL 中的 SELECT 语法的确提供了这个功能,一般来说我们只从一个表中查询数据,通常不需要增加一个固定的常数列,但如果我们想整合不同的数据源,用常数列作为这个表的标记,就需要查询常数。 比如说,我们想对 employees 数据表中的员工姓名进行查询,同时增加一列字段 corporation ,这个字段固定值为“阿里巴巴”,可以这样写 :
# 常数 SELECT '阿里巴巴' as corporation, last_name FROM employees;
显示表结构
# 显示表结构 DESCRIBE employees; DESC employees;
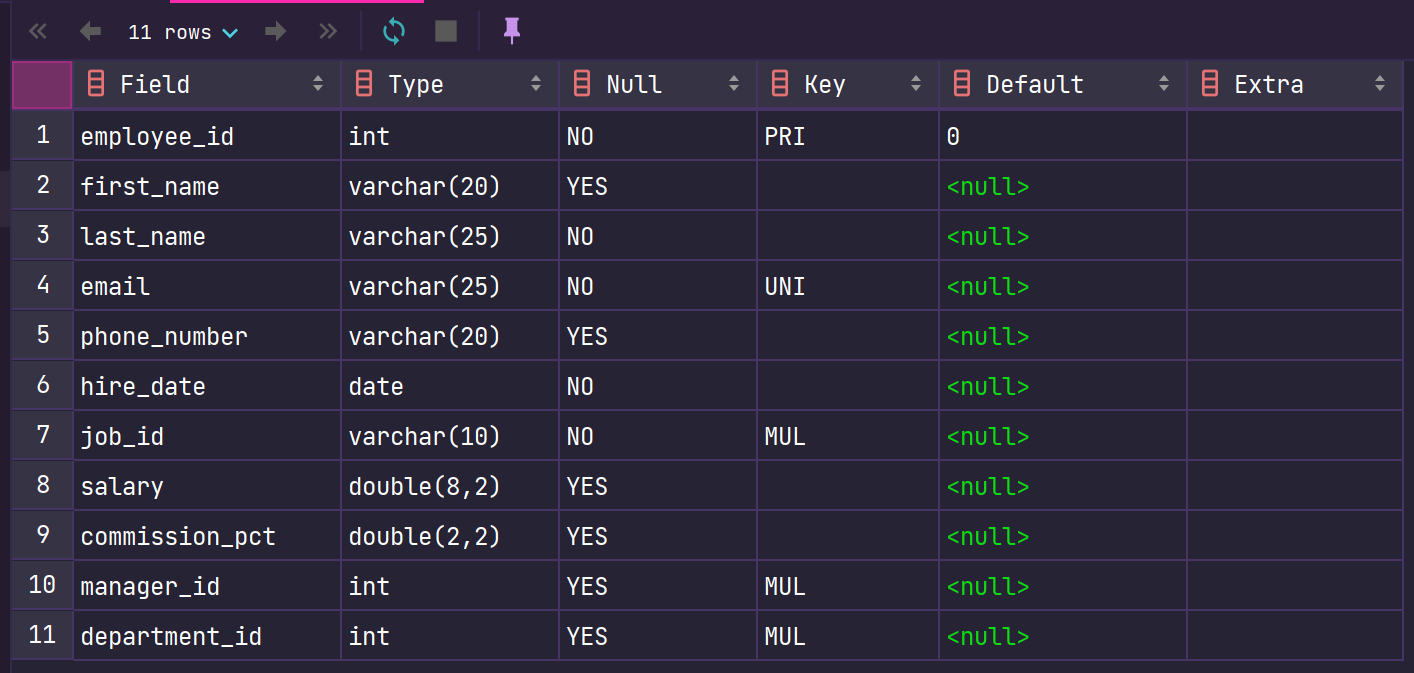
其中,各个字段的含义分别解释如下 :
- Field:表示字段名称。
- Type:表示字段类型,这里 barcode、goodsname 是文本型的,price 是整数类型的。
- Null:表示该列是否可以存储NULL值。
- Key:表示该列是否已编制索引。PRI表示该列是表主键的一部分;UNI表示该列是UNIQUE索引的一部分;
- MUL表示在列中某个给定值允许出现多次。
- Default:表示该列是否有默认值,如果有,那么值是多少。
- Extra:表示可以获取的与给定列有关的附加信息,例如AUTO_INCREMENT等
过滤数据
语法 :
SELECT 字段1,字段2 FROM 表名 WHERE 过滤条件
使用WHERE 子句,将不满足条件的行过滤掉 , WHERE子句紧随 FROM子句
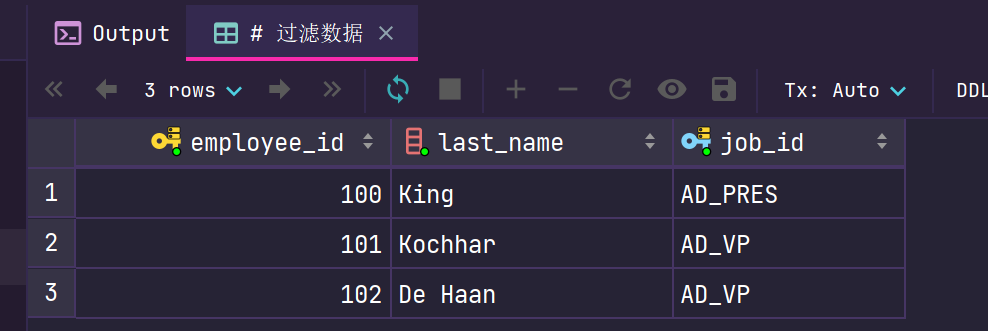
# 过滤数据 SELECT employee_id, last_name, job_id FROM employees WHERE department_id = 90;
本文作者:王天赐
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!